ToDo list in Autumn 2024
ToDo
This document provides an overview of NinjaLABO’s tasks and objectives for the autumn of 2024. The following sections outline key areas of focus, ranging from way of working (WoW) to model development and hardware deployment strategies.
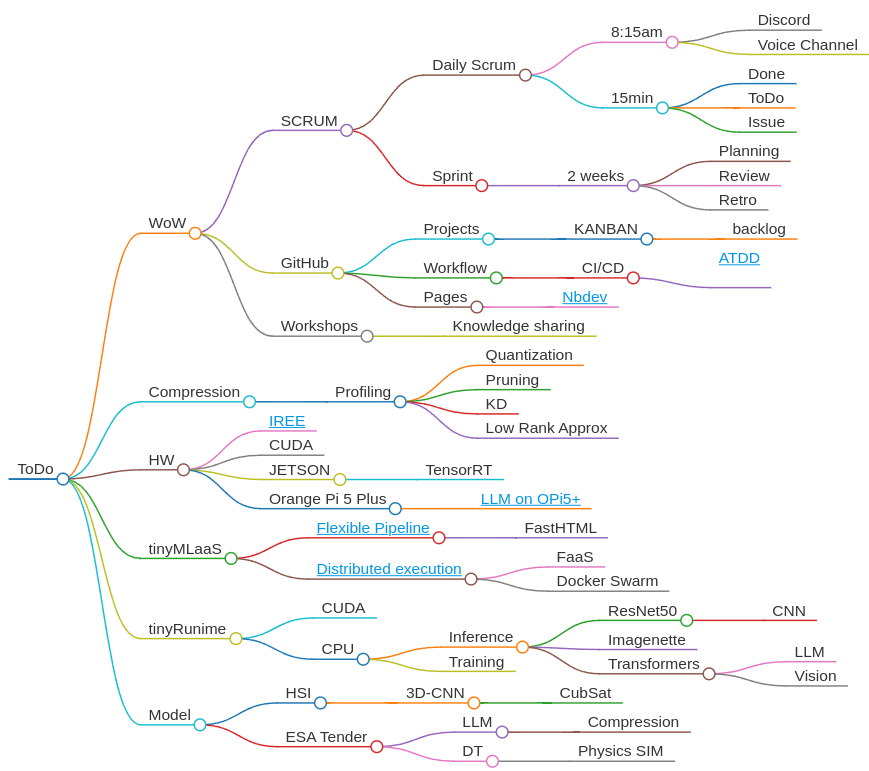
WoW
Our Way of Working (WoW) aims to ensure efficient and collaborative work among team members. This includes SCRUM practices, GitHub workflows, and workshops for knowledge sharing.
SCRUM
SCRUM is our core agile framework, promoting daily check-ins, iterative sprint cycles, and continuous improvement.
Daily Scrum
8:15am
- Held on Discord in the Voice Channel.
- A strict 15-minute standup where everyone declares the following:
- What they completed (Done).
- What they will work on next (ToDo).
- Any blockers or issues (Issue).
Rule:
If a topic takes longer than 5 minutes, continue the discussion in backlog item comments or schedule another meeting.
Sprint
2-week cycle
Each sprint follows a clear structure, from planning to review, ensuring that we meet our project goals while continuously improving.
1. Planning
- Backlog grooming and sprint planning usually take place on Monday morning at the beginning of the sprint.
- The team selects high-priority tasks from the backlog.
2. Review
- The review occurs on Friday afternoon at the end of the sprint.
- We assess completed backlog items and discuss progress with stakeholders.
3. Retrospective (Retro)
- After the review, we hold a retrospective to discuss what worked well and what could be improved in our WoW.
- The retro typically happens right after the review on Friday afternoon.
GitHub
GitHub is our primary tool for project management, code reviews, and CI/CD.
Projects
KANBAN
- We use the KANBAN board to visualize and track our backlog items, ensuring we stay on top of tasks and priorities.
Workflow
CI/CD
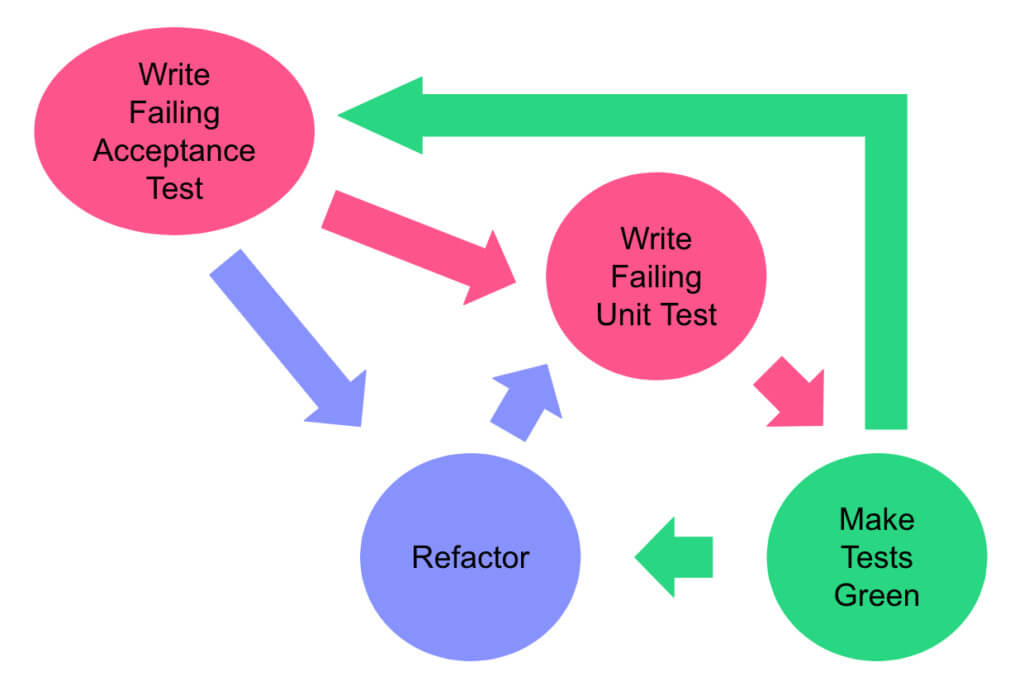
- We follow the Acceptance Test-Driven Development (ATDD) approach, which ensures that tests are written based on the system’s behavior before the implementation.
Pages
- Using Nbdev, we streamline writing, testing, documenting, and distributing software packages directly from Jupyter Notebooks.
Workshops
To facilitate knowledge sharing, we conduct workshops, encouraging developers to present and follow along using Jupyter notebooks.
Compression
The following techniques will be our focus for optimizing model performance:
Profiling
In-depth profiling is necessary to guide our compression strategies.
Quantization
- Reducing the number of bits needed to represent weights and activations with Post-training Quantization.
Pruning
- Pruning involves removing less critical parameters from the model.
Knowledge Distillation (KD)
- Training a smaller model (student) to mimic a larger model (teacher) through Knowledge Distillation.
Low-Rank Approximation
- Reducing model complexity by approximating weight matrices with Low-Rank Factorization.
HW
Exploring hardware platforms and their capabilities.
IREE
- Investigate the potential of using IREE for machine learning workloads.
CUDA
- Continue optimizing and leveraging CUDA for GPU-accelerated tasks.
JETSON
TensorRT
- Benchmark and compare model performance with NVIDIA’s TensorRT on Jetson devices.
Orange Pi 5 Plus
LLM on OPi5+
- Running Large Language Models (LLM) on the Orange Pi 5 Plus, evaluating its performance and scalability.
tinyMLaaS
Our tinyMLaaS focuses on providing scalable machine learning services, particularly for resource-constrained devices.
Flexible Pipeline
- A pipeline for flexible model transformations, such as compression, dockerization, and packaging models for various environments.
FastHTML
- Leveraging FastHTML for quicker model transformations and deployment.
Distributed Execution
- Distributed model execution across nodes, utilizing technologies like FaaS (Function as a Service) and Docker Swarm.
tinyRuntime
Our custom runtime for executing deep learning models on various hardware platforms.
CUDA
- Focus on improving GPU acceleration within our runtime.
CPU
- CPU-based inference and training optimizations.
Inference
ResNet50
- Evaluating inference performance with the ResNet50 model.
CNN
- Using Convolutional Neural Networks (CNN) to process image data.
Imagenette
- Benchmarking with the Imagenette dataset.
Transformers
- Supporting inference of Transformers, including Large Language Models (LLMs) and Vision Transformers.
Training
- Optimizing training pipelines on both CPU and CUDA-based platforms.
Model
Model development and collaboration projects for 2024.
HyperSpectral Imaging (HSI)
3D-CNN
- Developing models for hyperspectral imaging using 3D Convolutional Neural Networks, particularly for CubeSat applications.
ESA Tender
Large Language Model (LLM)
- Focusing on compression techniques for LLMs, making them more efficient for deployment.
Digital Twin (DT)
- Exploring physics simulation models as part of the ESA tender.