Summer Insights: Evolving tinyMLaaS with Flexible Pipelines and Distributed Execution
This summer, our team embarked on an ambitious journey, iterating through eight MVP releases of our tinyMLaaS platform, which focuses on deep neural network (DNN) model compression within a SaaS environment. The feedback we received from a diverse group of reviewers was invaluable—your insights and suggestions were instrumental in shaping the future direction of our platform. Through this collaborative effort, we identified two significant architectural enhancements that are crucial for improving the flexibility and scalability of tinyMLaaS. These enhancements focus on two key areas: abstracting the model transformation process through flexible pipelining and enabling distributed execution of these transformations across various virtual machines (VMs).
Flexible Pipelining for DNN Model Transformations
At the heart of DNN model compression lies a series of transformations applied to pre-trained models. These transformations are essential for optimizing models, reducing their size, and minimizing computational demands while maintaining accuracy. The term “DNN model” covers a broad spectrum, from a pure saved representation of computationa grapgh (e.g. a seris of feedforward networks, convolutional and recurrent networks) to an installable OS / docker container images, where a model comes with its runtime enviroments).
In the early stages of tinyMLaaS, our platform supported two primary types of transformations: the compiler and the installer:
Compiler: This component applies a variety of compression techniques, both hardware-independent and hardware-aware. These include methods such as quantization (which reduces the precision of the model’s weights), layer fusion (which merges layers to streamline computation), and pruning (which removes redundant or less critical neurons). The goal is to shrink the model’s footprint and speed up inference without significantly sacrificing accuracy.
Installer: After compression, the installer packages the model with a runtime execution environment, preparing it for deployment in various formats. This could involve creating an installable operating system image or a Docker container that encapsulates everything needed to run the model.
While these transformations proved effective, we recognized a limitation in treating them as distinct processes. By abstracting these processes into a unified concept we now refer to as a transformer, we introduce the ability to create more flexible and modular pipelines. With this new approach, any number of transformers, of any type, can be sequentially applied to a DNN model. This flexibility allows us to customize the compression and packaging workflow to suit the specific needs of each project or use case, enabling the creation of more complex and tailored solutions.

For instance, a user could now chain multiple transformations, such as applying quantization, followed by pruning, and then wrapping the final model in a Docker container, all within a single streamlined pipeline. This modularity also opens the door to integrating new and emerging techniques into the pipeline, ensuring that tinyMLaaS remains at the cutting edge of model compression technology.
Distributed Execution of Model Transformations
In our initial design, tinyMLaaS operated on a single, large GPU machine. This centralized approach was chosen for simplicity, but as we explored real-world use cases, we encountered several challenges that highlighted the need for a more distributed architecture.
One significant issue arose with Quantization Aware Training (QAT), a technique where the model is retrained with quantization in mind to maintain accuracy post-compression. QAT requires the use of large datasets, which, in our original setup, had to be uploaded to our cloud infrastructure. This process not only consumed considerable time but also raised concerns among customers who needed to keep their proprietary data on-premises for security and compliance reasons.
To overcome these challenges, we are evolving tinyMLaaS to support distributed execution of model transformations. In this enhanced architecture, tinyMLaaS would continue to function as a control panel hosted in our data center. However, the actual processing of the models—whether it’s compression, packaging, or retraining—would take place on VMs located within the customer’s environment. This setup allows customers to maintain full control over their data, using their own computational resources to perform the necessary transformations. The benefits are twofold: it significantly reduces data transfer times and enhances security by keeping sensitive data within the customer’s infrastructure.
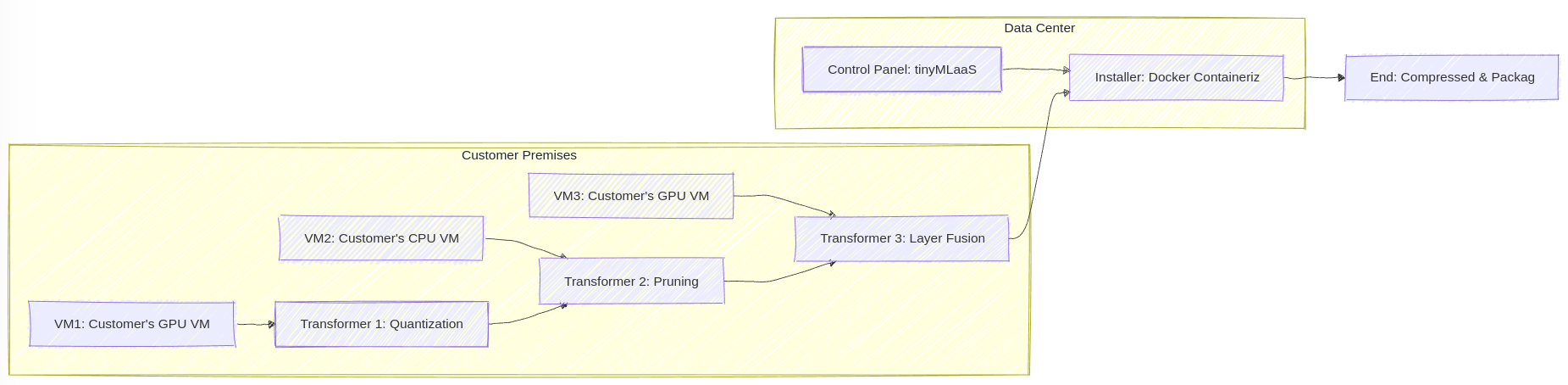
Our platform’s current components, the compiler and installer, are already encapsulated as Docker containers. This containerization is a crucial advantage as it allows us to seamlessly integrate distributed execution. The missing piece was the ability to specify where each transformer should be executed. We are addressing this by leveraging Docker Swarm, a powerful tool for orchestrating distributed systems. Docker Swarm enables us to manage a cluster of VMs, dynamically assigning tasks based on the specific characteristics and capabilities of each VM. This orchestration allows us to distribute the transformation workload intelligently, whether on-premises or in the cloud, optimizing for performance, security, and efficiency.
Conclusion
The two architectural changes we’re implementing—flexible pipelining of DNN model transformations and distributed execution—are not just incremental improvements; they are transformative steps forward for the tinyMLaaS platform. These enhancements are driven by the real-world challenges and feedback we’ve encountered during our MVP iterations, ensuring that tinyMLaaS is equipped to meet the evolving needs of edge AI and model compression.
As we look to the future, we are eager to bring these innovations to life and continue pushing the boundaries of what tinyMLaaS can achieve. We believe these changes will empower our users to tackle more complex problems, deploy models more efficiently, and maintain the highest standards of security and scalability.
Thank you again to everyone who contributed feedback and ideas—your input is shaping the future of tinyMLaaS, and we’re excited to continue this journey together.
References
- Quantization Aware Training: A method that simulates the effect of quantization during training, allowing for more accurate compressed models. For more details, see Quantization Aware Training.
- Docker Swarm: A native clustering and orchestration tool for Docker, enabling the management of a cluster of Docker nodes as a single virtual system. Learn more about Docker Swarm here.
- Model Compression Techniques: An overview of various DNN model compression techniques can be found in this comprehensive review.