tinyRuntime review
Introducing tinyRuntime: A Lightweight Runtime for ML Models
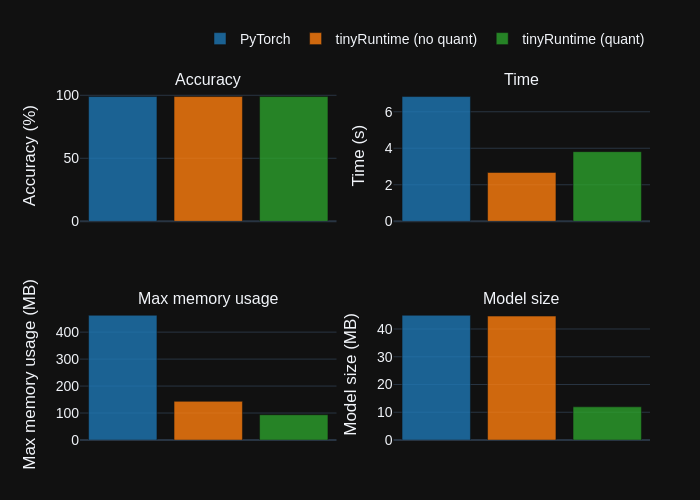
In the evolving landscape of machine learning, efficient model deployment is paramount, especially in resource-limited environments. That’s where tinyRuntime comes in—a lightweight runtime designed to facilitate the fast inference of compressed ML models. Current tinyRuntime performance compared to PyTorch can be checked on our performance page.
What is tinyRuntime?
Written in C, tinyRuntime is engineered for optimal performance on arm64 and x86 architectures. It addresses the growing need for a runtime that operates efficiently with minimal dependencies, making it ideal for applications where memory and computational resources are constrained.
Key Benefits of tinyRuntime
- Fast: tinyRuntime is optimized for speed, enabling quick model inference that can meet the demands of real-time applications.
- Lightweight: With significantly lower memory requirements compared to traditional frameworks like PyTorch, tinyRuntime ensures that even devices with limited resources can effectively run ML models.
- Scalable: Its design allows for scalability across various applications and use cases, making it adaptable to different industry needs.
Challenges Ahead
While tinyRuntime offers significant advantages, it does come with its own set of challenges:
- Maintenance Effort: The custom implementation of tinyRuntime necessitates ongoing effort to maintain and update the codebase, ensuring it remains efficient and relevant.
- Hardware Support: Providing broad support for diverse hardware platforms and various ML architectures can be challenging, necessitating continuous optimization.
Next Steps
Moving forward, our focus will be on:
- Continued Optimization: We will work on enhancing performance and expanding support for different hardware and ML architectures, ensuring tinyRuntime remains competitive and efficient.
- Exploring Alternatives: We are considering exploring other runtimes like IREE, which already supports a variety of hardware. This could provide insights and solutions that may benefit tinyRuntime’s development.
Conclusion
tinyRuntime is paving the way for efficient ML model inference in resource-constrained environments. With its fast performance and lightweight design, it can be an option for developers and organizations looking to deploy machine learning solutions effectively. We invite you to follow our journey as we continue to enhance tinyRuntime and explore new possibilities in the world of machine learning.