TinyML as-a-Service Overview
What is TinyML / AI Compression
TinyML involves deploying machine learning models on small, resource-constrained devices, such as microcontrollers or edge devices. The objective is to enable these devices to perform intelligent tasks without relying on powerful servers or the cloud. AI Compression involves techniques to reduce the size and computational requirements of AI models, making them suitable for deployment on smaller devices without significantly sacrificing performance. Techniques include Quantization (reducing precision), Fusing (combining layers), Factorization (breaking down complex operations), Pruning (removing unimportant neurons), and Knowledge Distillation (transferring knowledge from a large model to a smaller one).
TinyML isn’t limited to microcontrollers with constrained resources. A core concept of TinyML is the Machine Learning Compiler (ML Compiler), which compiles pre-trained models into small, optimized executables. This approach can be applied to large deep neural network (DNN) models, such as large language models (LLMs), to reduce operational expenses (OPEX) in datacenters.
The Two Phases of Deep Neural Networks (DNNs)
- Training Phase: In this phase, the AI model learns from data. This involves feeding the model large datasets and iteratively adjusting its parameters to minimize prediction errors. The training phase requires significant computational power and is usually performed on powerful servers or cloud infrastructure.
- Inference Phase: This is the phase where the trained model is used to make predictions or decisions based on new data. Unlike the training phase, inference can occur on much smaller devices, making it practical for real-world applications where quick responses are needed, and continuous connectivity to powerful servers is impractical.
Currently, our focus is on Post-Training Quantization (PTQ) and other post-training compression techniques, which are crucial for making models efficient enough to run on limited hardware.
TinyML as-a-Service / AI Compression as-a-Service Workflow
The provided diagram outlines a streamlined process to make AI models efficient and deployable on small devices.
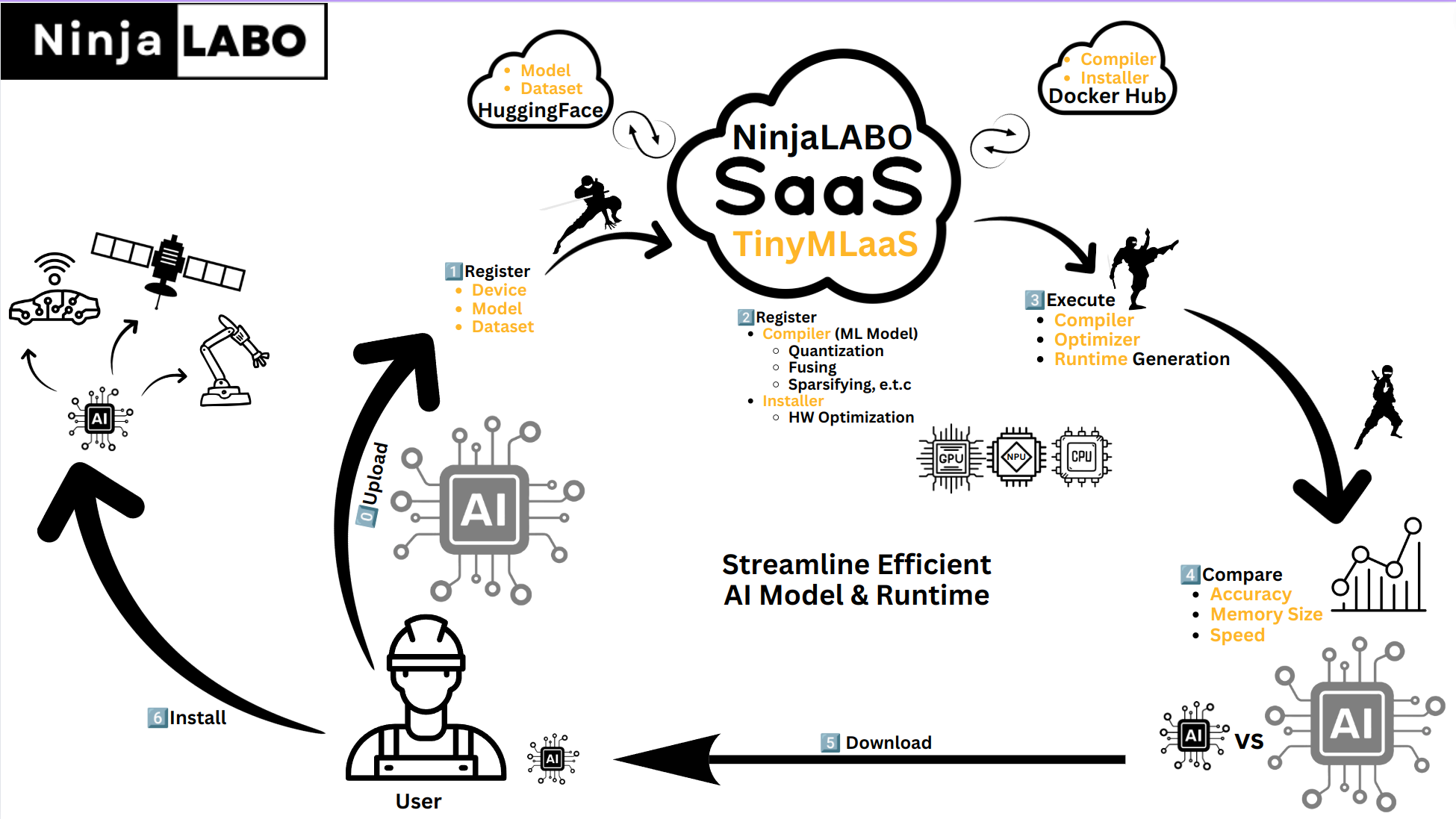
Here’s a detailed explanation of each step:
- Upload:
- Users upload their AI models, datasets, and information about their devices to the TinyMLaaS platform. The platform uses Huggingface storage for managing these uploads, ensuring secure and efficient handling of the data.
- Register:
- The platform registers the user’s device, model, and dataset. This step involves creating records of the hardware specifications, model details, and dataset characteristics, ensuring the platform understands the user’s specific requirements.
- Register Compiler:
- The platform registers a compiler tailored for the machine learning model. This compiler employs various optimization techniques such as:
- Quantization: Reducing the precision of the model’s calculations, which decreases the model size and computational load.
- Fusing: Combining multiple layers of the model to streamline operations.
- Sparsifying: Removing less important parts of the model to further reduce its size.
- Pruning: Eliminating redundant or less significant neurons in the model, reducing complexity.
- Knowledge Distillation: Training a smaller model to mimic the behavior of a larger model, transferring its knowledge efficiently.
- Additionally, the platform registers an installer that handles hardware optimization and can support software over-the-air updates (SOTA) for seamless deployment.
- The platform registers a compiler tailored for the machine learning model. This compiler employs various optimization techniques such as:
- Execute:
- The platform executes the compiler and optimizer, generating a custom runtime environment. This process transforms the original AI model into a more compact and efficient version, specifically tuned to run on the user’s hardware.
- Compare:
- Users can compare the original and optimized models based on metrics such as accuracy, memory size, and speed. This comparison helps ensure that the optimized model still meets the necessary performance criteria while being more efficient.
- Download:
- Users download the optimized model for installation on their devices. In some cases, if SOTA is supported, the TinyMLaaS platform can directly install the model onto the devices.
- Install:
- Users install the optimized AI model on their device, setting it up to run efficiently. This step is crucial for enabling the device to perform intelligent tasks, leveraging the compressed model for real-time inference.
Key Points to Understand
- Streamlined Process: The process is designed to be straightforward and user-friendly, even for those who are not experts in AI or machine learning.
- Flexibility: The platform supports registering any compiler and installer as Docker images, allowing for flexible and customizable pipelines.
- Efficiency: The service focuses on making AI models smaller and faster without significantly sacrificing accuracy, enabling deployment on devices with limited resources.
- Deployment: Optimized AI models can be deployed on various devices, from industrial robots to satellites, making the technology versatile and widely applicable.
By using TinyMLaaS, users can leverage advanced AI capabilities on small devices. This is particularly useful for applications that require low latency, privacy, and reduced reliance on constant internet connectivity, without needing deep expertise in AI compression techniques. Additionally, the ML Compiler approach can be applied to large DNN models to reduce operational costs in datacenters, making it a versatile solution across different scales and use cases.