Comprehensive Overview of DNN Model Compression Techniques
DNN Model Compression Techniques
Deep Neural Networks (DNNs) have achieved remarkable success across various domains, from image recognition to natural language processing. However, their deployment, especially in resource-constrained environments like mobile devices or edge computing, is often hindered by their size and computational demands. Model compression techniques are essential to address these challenges, enabling the use of DNNs in real-world applications without sacrificing too much performance. This article provides a comprehensive overview of the major DNN model compression techniques, presenting a big picture of how each approach contributes to making neural networks more efficient.
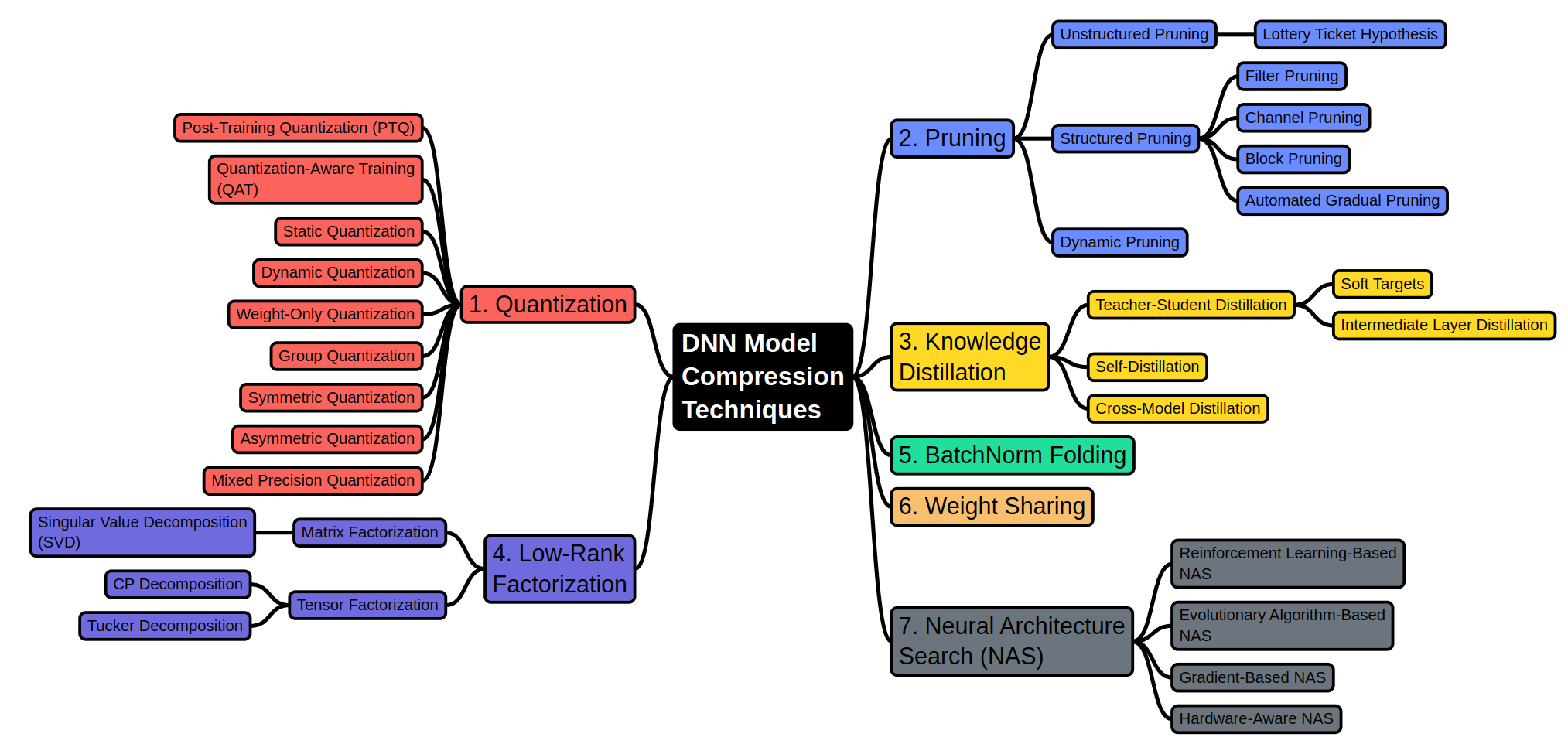
1. Quantization
Quantization reduces the precision of the numbers representing model parameters, thus decreasing the memory and computational requirements. There are several quantization approaches and methods, each of which can be used independently or in combination to optimize model performance.
Quantization Approaches: - Post-Training Quantization (PTQ): This technique converts the weights and activations of a pre-trained model to lower precision (e.g., from 32-bit floating point to 8-bit integers) without requiring further training. - Quantization-Aware Training (QAT): Unlike PTQ, QAT involves training the model with simulated quantization effects, allowing the network to learn to be robust to the lower precision. This typically results in better performance compared to PTQ. Quantization Methods: - Static Quantization: Quantizes weights and activations using a representative dataset. All required quantization parameters are calculated beforehand, making inference faster compared to dynamic quantization. - Dynamic Quantization: Applies quantization to activations dynamically during inference. This method adapts to varying data more effectively than static quantization, providing flexibility for data with a wide range of values. - Weight-Only Quantization: Focuses on quantizing only the model weights while keeping activations at a higher precision. This approach can help maintain model accuracy compared to quantizing both weights and activations, but it results in a larger memory footprint. - Group quantization: Quantizes weights in predefined groups separately, allowing more precise control and potentially better trade-offs between accuracy and memory size. - Symmetric vs. Asymmetric Quantization: Symmetric quantization uses a single scale for both positive and negative values, while asymmetric quantization allows addionally zero-points (shifting values), , fully utilizing the quantization range. Symmetric quantization is generally faster, whereas asymmetric quantization offers improved accuracy. - Mixed Precision Quantization: Utilizes different precision levels (e.g., 16-bit floating point, 8-bit integers) within the same model. This method selects precision dynamically based on the importance of different layers or operations and can be combined with various quantization techniques to optimize performance and efficiency.
Each quantization method can be used in combination, depending on the specific needs of the model and deployment scenario. By effectively applying these techniques, you can achieve a balance between model accuracy, computational efficiency, and resource usage.
2. Pruning
Pruning involves removing less important parameters (e.g., weights, neurons, filters) from the network, effectively “trimming” the model without significant loss in performance. Pruning can be categorized into:
- Unstructured Pruning: Removes individual weights based on certain criteria, such as magnitude-based pruning, where weights with the smallest magnitude are removed. This type of pruning can lead to sparse matrices that are harder to accelerate on standard hardware.
- Lottery Ticket Hypothesis: Suggests that within a large network, there exist smaller subnetworks (“winning tickets”) that can be trained to achieve performance similar to the original network.
- Structured Pruning: In contrast to unstructured pruning, this method removes entire structures, such as filters or channels, making the resulting model more hardware-friendly.
- Filter Pruning: Removes entire filters in convolutional layers.
- Channel Pruning: Prunes entire channels across feature maps.
- Block Pruning: Removes blocks of weights or layers.
- Automated Gradual Pruning: Gradually removes parameters during training based on a predefined schedule, as implemented in tools like FasterAI.
- Dynamic Pruning: Adjusts the pruning strategy during inference or training based on runtime conditions, ensuring the model adapts to changing computational constraints.
3. Knowledge Distillation
Knowledge Distillation is a technique where a smaller “student” model is trained to mimic the behavior of a larger “teacher” model. The student model learns not only from the labeled data but also from the soft predictions of the teacher, which provides richer information about the data.
Teacher-Student Distillation: The classic approach where the student model is trained using the outputs of a pre-trained teacher model.
- Soft Targets: The student model is trained to match the teacher’s softened outputs (probabilities) rather than the hard labels.
- Intermediate Layer Distillation: The student learns from the intermediate representations of the teacher model, not just the final output.
Self-Distillation: A single model distills knowledge from itself by using its own predictions from previous training iterations as targets.
Cross-Model Distillation: Distillation occurs between different types of models, such as distilling from an ensemble of models to a single student model.
4. Low-Rank Factorization
Low-Rank Factorization reduces the dimensionality of the model parameters by decomposing matrices or tensors into products of lower-dimensional entities:
- Matrix Factorization:
- Singular Value Decomposition (SVD): Decomposes weight matrices into products of smaller matrices, effectively reducing the model size.
- Tensor Factorization:
- CP Decomposition: Decomposes tensors (multi-dimensional arrays) into sums of outer products of vectors.
- Tucker Decomposition: Generalizes matrix decomposition to higher dimensions by decomposing a tensor into a core tensor multiplied by matrices along each mode.
5. BatchNorm Folding
BatchNorm Folding combines Batch Normalization layers with preceding layers to reduce the computational load during inference. BatchNorm layers are merged with the preceding convolutional or fully connected layers during inference, reducing the number of operations. This is not an approximation; it means you can achieve model compression without sacrificing accuracy.
6. Weight Sharing
Weight Sharing is a technique used in neural networks to reduce the number of parameters, thus improving computational efficiency and potentially enhancing generalization. The core idea is to use the same weights across different parts of the network, which can lead to significant reductions in model size and complexity.
7. Neural Architecture Search (NAS)
Neural Architecture Search automates the design of neural networks, optimizing them for specific constraints, such as size, speed, or accuracy:
- Reinforcement Learning-Based NAS: Uses reinforcement learning to explore different architectures.
- Evolutionary Algorithm-Based NAS: Applies evolutionary strategies to evolve network architectures over successive generations.
- Gradient-Based NAS: Utilizes gradients to guide the search for optimal architectures.
- Hardware-Aware NAS: Tailors the search to optimize architectures specifically for target hardware, balancing performance with computational efficiency.
Resources
Here are the links that you provided and which were used as sources in the discussion:
MIT Efficient AI Course - Fall 2024
MIT Efficient AI Course - Fall 2024A Visual Guide to Quantization by Maarten Grootendorst
A Visual Guide to QuantizationFasterAI by Nathan Hubens
FasterAI