--- title: Pipeline interactions --- sequenceDiagram actor User participant Endpoint participant Database participant Volume participant HuggingFace participant DockerClient note over User,Volume: New run User->>Endpoint: Create a new run Endpoint->>+Database: add record Endpoint->>+Volume: create new directory as run volume Endpoint-->>User: 201 CREATED note over User,HuggingFace: Download Model & Dataset from Hugging Face User->>+Endpoint: Download model & dataset from HF Endpoint-->>+HuggingFace: verify access to HF ID HuggingFace-->>-Endpoint: confirm accessibility Endpoint-->>HuggingFace: request downloading Endpoint->>Database: add record of resource 'status'=running HuggingFace->>Volume: download Endpoint->>Database: update resource 'status'=generated Endpoint-->>-User: 200 OK note over User,Volume: Upload customized Model & Dataset User->>+Endpoint: Upload model & dataset Endpoint-->>Volume: upload temporary file & request extracting / copying to run directory Endpoint->>Database: add record of resource 'status'=running Volume->>Volume: extracting .zip / copying model.pkl Endpoint->>Database: update resource 'status'=generated Endpoint-->>-User: 200 OK note over User,DockerClient: Compile model User->>+Endpoint: Compile model Endpoint->>Volume: update compression configurations Endpoint->Volume: spawn Docker container Volume->>+DockerClient: with mounted model & dataset Endpoint->>Database: update resource 'status'=running DockerClient->>DockerClient: run & remove container DockerClient->>-Volume: update results to run directory Endpoint->>Database: update resource 'status'=generated Endpoint-->>-User: 200 OK note over User,DockerClient: Install model on device User->>+Endpoint: Register device Endpoint->>Database: add records of device information Endpoint-->>-User: 201 CREATED User->>+Endpoint: Install model on device Endpoint->>Volume: update runtime & device configurations Endpoint->Volume: spawn Docker container Volume->>+DockerClient: with mounted model & dataset Endpoint->>Database: update resource 'status'=running DockerClient->>DockerClient: run & remove container DockerClient->>-Volume: update results to run directory Endpoint->>Database: update resource 'status'=generated Endpoint-->>-User: 200 OK note over User,DockerClient: Run inference User->>+Endpoint: Run inference on device Endpoint-->>+Volume: extract inference image name Volume-->>-Endpoint: return image name (result of installation) Endpoint->Volume: spawn Docker container Volume->>+DockerClient: with mounted model & dataset Endpoint->>Database: update resource 'status'=running DockerClient->>DockerClient: run & remove container DockerClient->>-Volume: update results to run directory Endpoint->>Database: update resource 'status'=generated Endpoint-->>-User: 200 OK
Demistifying TinyMLaaS
Tech
TinyMLaaS
Brief overview of the technology behind NinjaLABO’s TinyML as-a-Service
Introduction to the TinyMLaaS
TinyMLaaS is an end-to-end service that supports the entire lifecycle of a machine learning (ML) model deployment - from dataset selection to running inference on real devices. This system streamlines the process by combining both frontend and backend services into a unified platform known as NinjaLABO Studio. This blog post will guide you through how the system functions, covering essential components like pipelines, artifacts, GitHub automation, Docker integration, and more.
Research and Performance
Our research results are published via a Landing Page that features documentation, research blogs, and performance reports. The page helps users stay updated with the latest performance benchmarks and model optimizations.
- Research Blogs: Published in formats such as .ipynb, .md, or .qmd using Quarto architecture.
- Performance Updates: Automated updates on model performance are triggered through GitHub Actions.
- HTML Page Generation: GitHub Actions are also employed to publish performance metrics and blog posts as .html pages for easy access through the landing page.
User experience with NinjaLABO Studio
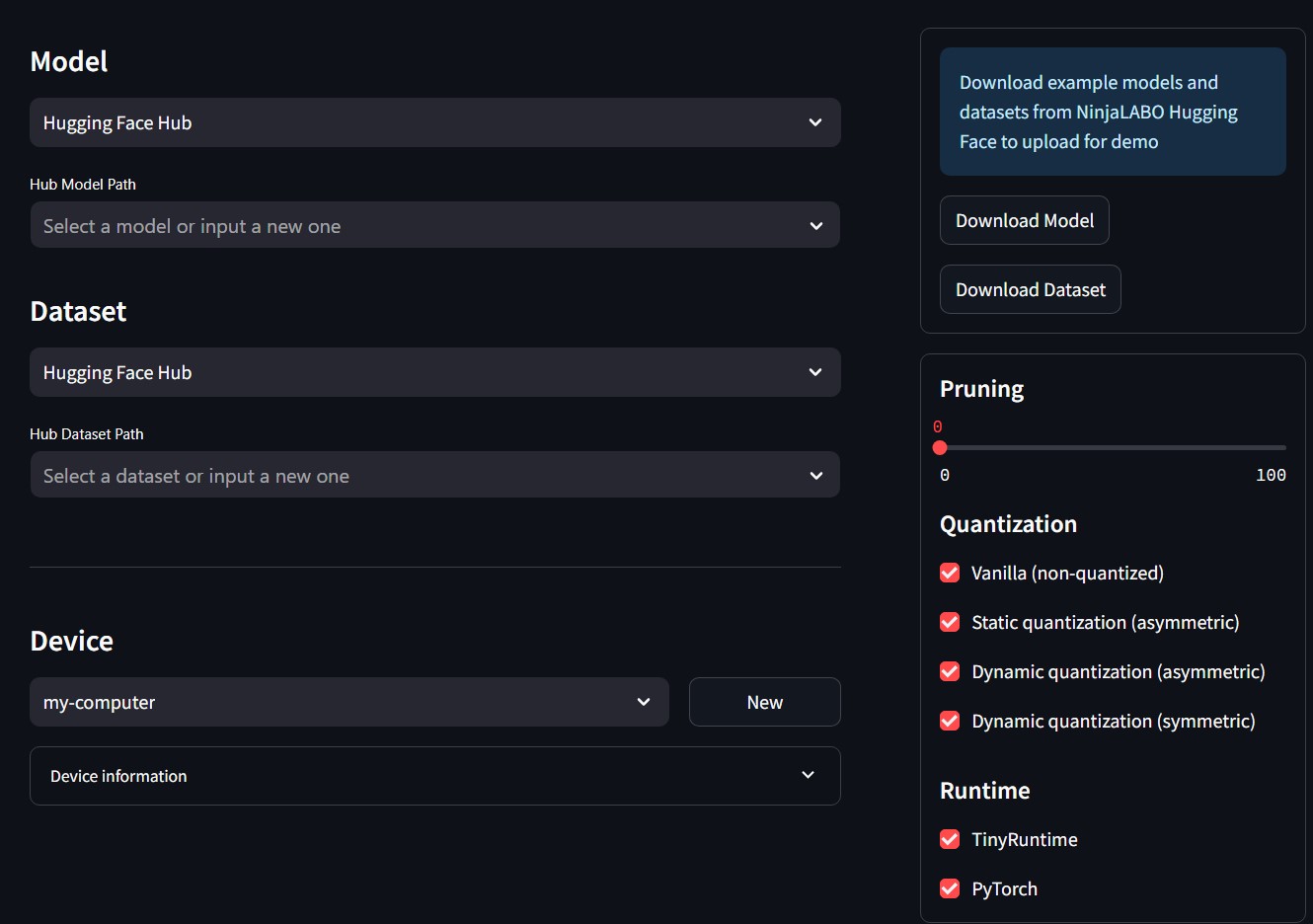
The functionalities of TinyMLaaS are delivered through its Studio interface, where users interact with the system. The Studio is constructed from coordinating a backend API developed with FastAPI and frontend interface built with Streamlit.
The Studio allows users to manage projects and monitor their deployment pipelines. Some notable features of the Studio include:
- Project dashboard: The configurations of deployment pipelines are simplified into a singular dashboard. The user can easily spawns multiple runs with different models, datasets, and compression techniques under a project.
- Result comparison and visualization: After multiple pipelines (runs) are complete, the user can compare their inference accuracy, execution time, and model size. The user can also visualize such differences and trade-off between these metrics to select the most suitable compression techniques.
- Upload models & datasets: The user can upload their own models and datasets following our accepted format.
- Export inference image: The user can export artifacts from their pipeline including the compressed model file and inference image to run on their local device.
- Email notifications: The user is notified about the pipeline status (success / error) via emails.
For more information about the user experience, please check out the walkthrough tutorial!
Components
TinyMLaaS utilizes a system with high-degree integration with Hugging Face and Docker, with the main components being:
- User: Entity representing the user’s requests through Studio.
- Endpoint: The API layer that handles requests and manages interactions with backend services.
- Database: Stores records related to models, datasets, runs, and their statuses.
- Volume: Dedicated storage for artifacts generated by Docker containers.
- Hugging Face: Provides access to pre-trained models and datasets.
- Docker Client: Executes tasks inside containers, including compiling models, installing models to a specified device, and running inference.
Interactions
The Studio operates via an API layer that coordinates user requests, Docker containers, Hugging Face datasets, and device installations to construct the deployment pipeline of a machine learning model on edge device. The pipeline steps are:
- Create a Run: A new run is created for a project, starting the entire process.
- Download or Extract Models and Datasets: The model is either fetched from Hugging Face or extracted from a user-provided file.
- Compile Model: The model is compiled inside a Docker container.
- Install Model on Device: The compiled model is installed on the specified device.
- Run Inference: Inference is executed using the test dataset on the device.
Conclusion
TinyMLaaS simplifies the entire machine learning model lifecycle, from research to deployment on edge devices. With seamless integration between Docker and Hugging Face, users can manage models, datasets, and pipelines through an intuitive Studio interface. By automating key tasks like model compilation, deployment, and performance monitoring, TinyMLaaS enables fast, efficient edge AI development, making it a powerful solution for professionals and researchers alike.